
Back-propagation을 통해 신경망을 학습하는 과정에 대한 내용을 다룬다.
논문의 원본은 여기에서 볼 수 있다.
이번 논문에서는 새로운 학습 방법인 back-propagation에 대해서 다룬다. 해당 학습 과정은 반복적으로 뉴런들 사이의 연결 가중치를 조절해서, 신경망의 결과와 실제로 사용자가 기대했던 결과 사이의 오차를 최소화하도록 한다. 이런 학습 과정을 통해서 우리가 볼 수 있는 input/output layer가 아닌 hidden layer 들도 의미 있는 특성을 학습할 수 있고, 원하는 결과를 제공하기 위해 동작할 수 있다.
과거에 Self-organizing Neural Network(NN)를 위한 다양한 시도들이 있었다. 뉴런들 사이의 가중치를 업데이트해서 원하는 task를 수행할 수 있도록 하는 것이 목표였다. Input unit 과 output unit 사이에 hidden unit을 사용하면 입력에 명시하지 않은 다양한 feature 들을 학습할 수 있고, 많은 hidden unit들이 활성화되어야 원하는 task를 더 잘 수행할 수 있다. Input unit과 output unit 만으로 구성된 경우, symmetry를 학습하는데 제한적이다. 중간층(intermediate layer)을 사용하지 않으면 symmetric 한 구조를 학습할 수 없다. 단 2개의 hidden node를 사용한 예시는 [그림-1]에서 볼 수 있다.

Layered network에서 input layer는 가장 낮은(bottom) 층에 위치하고, output layer는 가장 높은(top) 층에 위치한다. 높은 층에서 낮은 층으로 연결을 불가능 하고, 같은 층 내에서의 연결 또한 불가능하다. 학습이 시작되면, 가장 낮은 층에서부터 가장 높은 층으로 학습이 진행된다. 이전 $ i $ 번째 뉴런의 출력을 $ y_i $라고 하고, $ i $ 번째 뉴런에서 $ j $ 번째 뉴런으로의 연결 가중치는 $ w_{ji} $라고 할 때, $ j $ 번 째 뉴런에 대한 가중 입력 $ x_j $ 는 다음과 같이 정의한다.

$ j $ 번 째 뉴런이 가중 입력 $ x_j $ 를 받았을 때 출력 $ y_j $ 는 다음과 같이 정의한다. 해당 식은 가중 입력에 대한 non-linear function으로 구성된다.
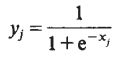
학습의 최종 목표는 우리가 원하는 task를 수행할 수 있는(우리가 기대하는 결과를 제공할 수 있는) 가중치(weight)를 찾아내는 것이다. 얼마나 우리가 원하는결과와 예측한 결과가 일치하는지 확인하기 위해서 Error를 정의할 필요가 있다. NN의 output을 $ y_{j,c} $라고 하고, 실제 기대하는 결과를 $ d_{j,c} $라고 할 때, 전체 에러(total error)는 다음과 같이 정의할 수 있다.

정확하게 가중치를 학습했다면, NN의 output과 실제 정답이 유사할 것이고, 그러면 전체 loss가 0에 가까워질 것이다. 그러므로, 학습을 통해서 에러를 최소화 시켜야 한다.
앞서 언급했듯이, 원하는 결과를 위해서는 정확학 가중치(weight)가 학습되어야 한다. 우리는 back-propagation을 통해서 한 가중치(weight)를 조금 변화시켰을 때, 해당 변화가 전체 에러(total error)에 어느 정도 영향이 있는지 확인하고, 전체 에러(total error)의 값을 최소화시키는 방향으로 가중치를 업데이트할 것이다. 이렇게 위에서부터 아래로 내려오면서 가중치를 업데이트하는 과정을 backward pass라고 부른다. Backward pass는 우선 전체 에러(total error) $ E $ 를 NN의 output $ y $ 에 대해서 미분하면서 시작한다. [식-3]을 $ y$ 에 대해서 미분하면 [식-4]를 구할 수 있다.

이후, [식-4]를 기반으로 chain rule을 적용하면 전체 에러 $ E $를 가중입력 $ x_j $ 에 대해 미분한 값을 구할 수 있다. [식-2]를 $ x $ 에 대해서 미분하면 $ y(1-y) $라는 값을 구할 수 있다. [식-5]를 통해 입력 $ x $ 가 전체 에러에 어느 정도의 영향을 끼치는지 알 수 있다.

동일한 방법으로 전체 에러 $ E $ 를 가중치(weight) $ w $ 에 대해서 미분하면 [식-6]을 구할 수 있다.

[식-1]에서 [식-6] 까지의 과정을 계속해서 반복하면서 학습을 진행할 수 있다.
$ dE / dw $ 를 사용하는 다양한 방법이 있는데, 그중 가장 간단한 방법은 가중치 (weight)를 미분한 값의 일부에 대해서만 업데이트를 진행하는 것이다. ([식-7] 참고) 이 방법은 상대적으로 느리게 수렴하지만, 쉽게 적용이 가능하다는 장점이 있다.

다른 방법으로는 acceleration method를 사용하는 방법이다. ([식-8] 참고) [식-8] 에서 $ \alpha $ 값은 0에서 1 사이의 exponential decay factor를 의미한다. (가중치 변화에 있어서 현재 gradient가 미치는 영향)
Gradient descent 방식의 가장 큰 문제점 중 하나는 global minimum이 아닌 local minimum에 갇혀 있을 수 있다는 것이다. 대부분의 경우 local minima에 멈추지 않지만, 그런 경우 몇 개의 connection을 더 생성하면 weight-space에 더 많은 차원을 제공할 수 있고, 이를 통해 local minima에서 벗어날 수 있다.
# 참고 논문
- Perceptrons : symmetric 한 문제를 학습하는 것에 대한 해결책




댓글