
우리가 흔히 말하는 빅데이터(big data)는 3V라는 특징을 가지고 있습니다.
- Velocity : 빠른 속도로 데이터가 증가합니다.
- Volume : 대용량의 데이터로 구성됩니다.
- Variety : 여러 형태의 데이터로 구성됩니다.
이러한 데이터는 인공지능(Artificial Intelligence, AI)에서도 중요한 역할을 하고 있습니다.
인공지능에서 입력은 반드시 데이터(자료)의 형태를 갖습니다.
인공지능을 이용한 핵심 기술은 크게 2가지로 볼 수 있는데, 음성인식(voice recognition)과 형상인식(pattern recognition) 입니다.
자율주행 자동차를 두 가지 기술을 모두 사용하는 미래 기술의 대표적인 예시로 들 수 있습니다.
자율주행 자동차에서 사용되는 인공지능에 제공되는 데이터도 반드시 어떠한 데이터의 형태를 갖습니다.
인공지능 모델은 입력한 데이터(자료)를 분석해서 최적의 분류(classification)을 하게 됩니다.
모집단과 표본
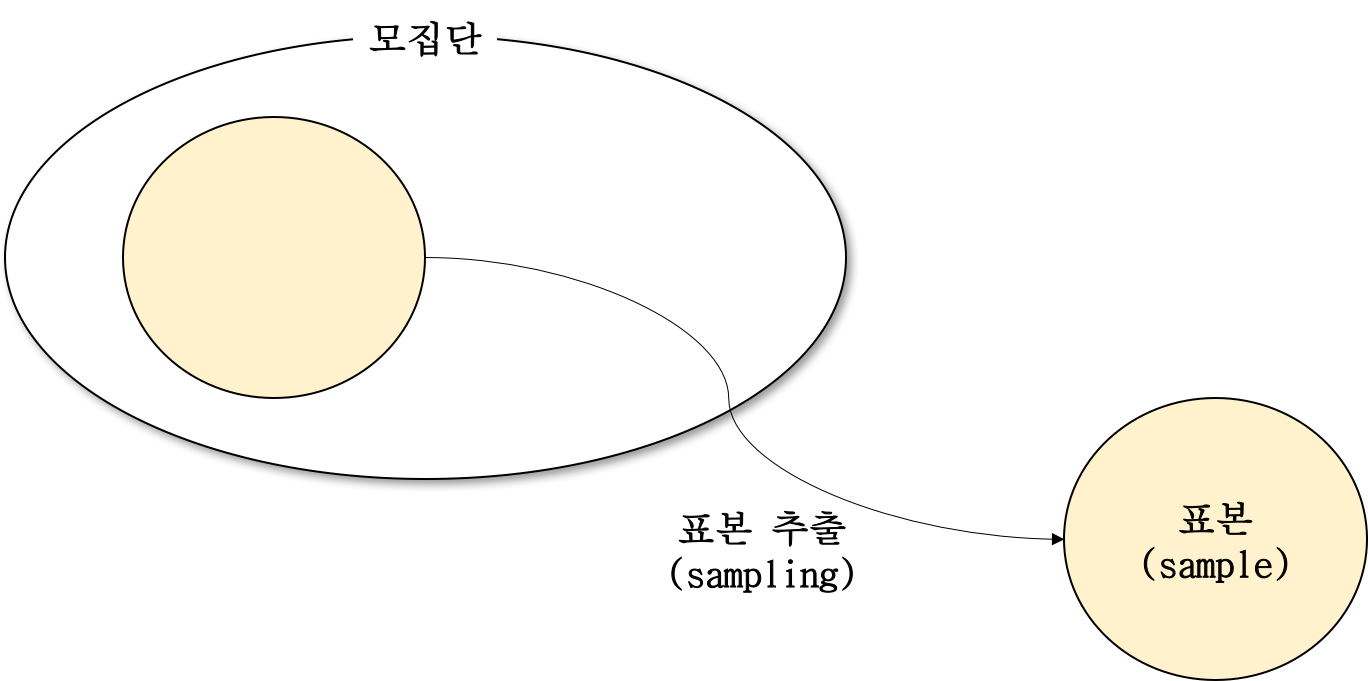
모집단(population)은 분석하고자 하는 전체 대상(집단)의 정보입니다.
전체 대상에 대한 정보를 수집한다면 제일 좋겠지만,
전체 대상의 규모가 크고 다양하기 때문에 전체 대상의 모든 정보를 수집하려먼 많은 경비와 시간이 요구됩니다.
그렇기 때문에 우리는 표본(sample)을 사용하게 됩니다.
표본(sample)은 모집단의 일부를 임의로 뽑아서 전체 모집단에 대한 정보를 추정하기 위해서 사용합니다.
R 사용법
R을 실제로 사용하기에 앞서서 주의해야할 점이 있습니다.
- R은 case sensitive 합니다. 그러므로, x와 X를 서로 다르게 인식합니다.
- R의 명령어는 ; 또는 새 줄로 구분합니다.
- 주석은 #로 시작하고, # 이후의 모든 문장은 주석으로 인식됩니다.
- 너무 긴 명령어는 +로 연결해서 사용할 수 있습니다.
R은 다양한 내장 기능(inbuilit facilities)이 있습니다. 대표적인 3가지 기능을 알아보겠습니다.
- help(명령어) : 해당 명령어의 사용법을 확인할 수 있습니다.
- example(명령어) : 해당 명령어의 예시 코드를 확인할 수 있습니다.
- demo(명령어) : 해당 명령어의 예시 코드와 실행 데모를 확인할 수 있습니다.
R에서 자체적으로 제공하는 내장 자료들이 있습니다.
data() 명령으로 내장 자료들의 목록을 조회할 수 있습니다.
내장 자료가 아니지만 라이브러리(library)를 통해서 제공되는 데이터도 있습니다.
패키지(package)는 라이브러리의 집합으로, 패키지를 먼저 install 후, 제공되는 데이터를 사용할 수 있습니다.
기본 연산
벡터 연산
R에서는 벡터 연산이 가능합니다.
x <- c(1, 2, 3, 4)
assign("x", c(1, 2, 3, 4))
c(1, 2, 3, 4) -> x위 예시는 1, 2, 3, 4로 구성된 column vector를 x 라는 변수에 할당하는 명령입니다.
3개의 명령이 모두 동일하게 동작합니다.
주의하셔야 하는 점은 두 번째 명령에서 할당하려는 변수명 x는 큰 따옴표("") 안에 기록해야 합니다.
x <- c(1, 2, 3, 4)
y <- (x, 0, x)
y
# 1 2 3 4 0 1 2 3 4 이전에 생성한 벡터를 새로운 벡터를 생성하는데 포함해서 사용할 수 있습니다.
수식 연산
20 / 7
# 2.857143
20 %/% 7
# 2
20 %% 7
# 620 / 7 연산에 대해서,
- / 연산은 두 수를 실수로 계산해서 소수점까지 결과를 제공합니다.
- %/% 연산은 나눗셈의 몫을 구할 때 사용합니다.
- %% 연산은 나누셈의 나머지를 구할 때 사용합니다.
x <- c(1, 2, 3, 4, 5, 6)
length(x)
# 6
sum(x)
# 21
mean(x)
# 3.5벡터를 참조하는 변수 x에 대해서,
- length() 는 벡터의 길이를 제공합니다.
- sum() 은 벡터에 포함된 모든 수의 합을 제공합니다.
- mean() 은 벡터에 포함된 모든 수의 평균을 제공합니다.
x <- c(1, 2, 3, 4, 5, 6)
sum((x-mean(x))^2) / (length(x) - 1)
# 3.5
var(x)
# 3.5위의 두 명령은 동일하게 표본분산을 제공합니다.
x <- c(1, 2, 3, 4)
rep(x, times=3)
# 1 2 3 4 1 2 3 4 1 2 3 4
rep(x, each=3)
# 1 1 1 2 2 2 3 3 3 4 4 4
c(1:10)
# 1 2 3 4 5 6 7 8 9 10rep() 함수는 입력으로 들어온 값을 반복해서 제공합니다.
times=n 옵션을 주면, 입력으로 들어온 값 전체를 n번 반복해서 제공합니다.
each=n 옵션을 주면, 입력으로 들어온 값의 각 원소를 각각 n번 반복합니다.
c(start:end) 는 start에서 end의 모든 값을 포함하는 벡터를 생성합니다.
seq(-5, 5, by 5)
# -5 0 5
seq(length=3, from=-5, by=5)
# -5 0 5seq() 함수는 수열을 생성합니다.
by 옵션으로 공차를 지정할 수 있습니다.
첫 번째 명령을 보면, -5에서 5까지 5간격으로 결과를 제공합니다.
두 번째 명령을 보면, -5에서 5 간격으로 3개의 결과를 출력합니다.
본 게시물은 K-MOOC <R을 이용한 통계학개론> 수업을 듣고 개인적으로 정리한 내용입니다.
잘못되었거나, 수정이 필요한 내용, 궁금한 내용이 있다면 언제든지 알려주세요!
자세한 강좌는 여기를 통해서 직접 수강하실 수 있습니다.
감사합니다 :)
'필기 노트 > R을 이용한 통계학개론' 카테고리의 다른 글
| [통계학 기초] 확률분포(probability distribution) (0) | 2020.07.17 |
|---|---|
| [통계학 기초] 확률(Probability) (0) | 2020.07.16 |
| [통계학 기초] 자료(data)의 종류, 중심과 퍼짐, 상관관계 (0) | 2020.07.15 |



댓글