
사람들의 일상 대화 속에서 사람의 특징(나이, 성별 등) 을 학습하는 방법에 대한 논문이다.
논문에서 사용한 모델의 코드는 여기, 데이터셋은 여기에서 확인할 수 있다.
논문의 원본은 여기에서 볼 수 있다.
Dialogue generation task에 있어서 다양한 challange 들이 존재하지만, personalized conversation 을 생성하는 방법 또한 큰 도전으로 남아있다. 실제 사람과 의미있는 대화를 주고받기 위해서는 현재 대화를 하고 있는 사람의 특징과 배경을 그 사람이 하는 말을 통해서 유추해낼 수 있어야 한다. [예시-1]을 보면 'brekky' 라는 단어를 통해서 현재 대화하고 있는 사람(H)이 호주에 있다는 것을 유추할 수 있다. 하지만, 다음 대화에서 사람(H)이 아이들과 방문할 만한 곳을 추천해달라는 요청에 대해서는 부적절한 대답을 제공한다는 것을 확인할 수 있다. 두 번째 대답을 통해 사용자는 어린 아이(kids)들과 함께 있다는 것을 유추할 수 있지만, 실제 시스템에서는 아이들과 가기엔 적합하지 않은 대답을 제공했다.

이번 논문에서는 이렇게 대화를 통해서 사용자의 personal knowledge base (PKB) 를 방법에 대해서 이야기한다. PKB를 사용하는데 있어서 몇가지 의문점이 생길 수 있다.
- 사용자의 personalized knowledge를 어떻게 정의할 것인가? : personalized knowledge는 사용자의 나이, 성별, 직업 등이 될 수 있고 사름 사람들과 관련된 결혼 여부, 친한 친구들의 이름 등이 될 수도 있다. 이번 논문에서는 사용자의 직업(profession) 과 성별(gender), 결혼 여부(family status), 나이(age) 로 제한하도록 한다.
- 그렇다면 이러한 knowledge를 어떤 식으로 사용자의 대화 속에서 유추할 수 있는가? : 실제로 wikipedia 등의 데이터셋에서 information extraction 을 수행하는 방식은 conversation에서 information extraction을 하기에 적합하지 않다. 대화(conversation)은 상대적으로 짧고, implicit 한 정보들을 많이 담고 있기 때문이다. 이러한 방식은 이번 논문에서 다룰 것이다.
- 이렇게 유추한 정보를 dialogue system에 어떻게 적용할 것인가? : 해당 주제는 이번 논문에서 직접적으로 다루지 않을 것이다.
# 기존 방식
Open-domain conversation model 들은 많은 데이터셋에 의존적이고 사용자가 다양한 방식으로 행동하는 것에 대해 robustness가 부족하다는 단점이 있다. 대화하는 상대의 explicit knowledge를 대화에 반영하는 몇개의 연구들이 있지만, 이러한 연구들도 상대의 정보를 explicit하게 참고한게 된다. 이렇게 explicit 한 정보를 그대로 반영하는 것이 제한적인 성능을 보인다는 것을 증명하기 위해서 oracle을 사용한다. Pattern-based 방식인 해당 orcale은 explicit하게 명시된 정보에 대해서 100% 정확하게 정보를 유추한다고 가정한다. 명시적으로 제시된 정보에 대해서 100%의 성능을 보이는 oracle도 이번에 제안하는 모델에 비해서 성능이 떨어진다는 것을 알 수 있는데, 이것은 상대에 대한 정보는 명시적인 정보를 통해서만 알 수 있는 것이 아니라, 대화에 내포된 간접적인 정보들(implicit information)이 더 많다는 것을 의미한다.
Personal Knowledge from Dialogues : 사용자의 배경(background knowledge)를 인지하는 것은 open-domain conversation 뿐만 아니라 goal-oriented conversation 에서도 중요한 역할을 한다. 사용자의 대화를 통해 사용자의 persona에 대한 임베딩을 생성하는 방식, 대화에서 information extraction을 수행하는 방식 등 다양한 방식들이 제안되었다. 하지만, 이런 방식을은 명식적(explicit)인 특정들에 의해서 학습된다는 문제가 있다.
Social media user profiling : Social media의 규모가 커지면서 사람들은 자신의 정보를 내포하고 있는 다양한 글을 social media에 포스팅하고 있다. 이러한 포스팅 중 일부는 실제 사람들 사이의 대화와 매우 유사한 경우도 있다. 과거에는 이러한 social media(Twitter, Facebook, Reddit 등)의 글들을 기반으로 사용자의 나이나 성별 등을 유추하는 방식들이 연구되어 왔다. 하지만 아직까지도 neural network를 이용한 연구들은 부족한 상황이다.
Neural models with attention : 최근에 attention을 이용한 다양한 모델들이 제안되었다. Conversation generation 에 있어서도 attention 기법은 다양하게 사용되고 있고, 각 utterance에 대해서 attention 을 고려하는 경우들이 대부분이다.
이번 논문에서는 Hidden Attribute Model (HAM) 이라는 모델을 제안한다. 이번 논문에서의 contribution은 다음과 같다.
- 대화를 통해서 상대의 특징을 인지할 수 있는 모델 (HAM) 제안.
- 영화 대본에서 가져온 대화 데이터셋에 대해서 profession, gender, age 의 정답을 추가한 데이터셋을 구축
- Reddit 의 대화 데이터에 대해서 profession, gender, age, familty status 를 추가한 데이터셋 구축
- Reddit, movie script dialogues, PersonaChat 을 대상으로 한 다양한 모델의 성능 비교
- 위의 데이터를 기반으로 한 transfer learning의 성능 분석
# 모델 : Hidden Attribute Models (HAMs)

HAM은 subject의 utterance를 기반으로 predicate에 해당하는 목록의 순서를 매겨서 제공하는 방식이다. 예를들어, [예시-2]에서 우리가 Edward의 직업(profession)에 대해서 유추하고자 한다면 predicate 은 profession에 해당한다. Edward에 대한 정보를 유추하기 때문에 subject는 Edward가 되고 policeman은 Edward의 profession에 대한 가장 높은 rank에 해당하게 된다. 정리하면, 우리는 subject $ S $ 와 predicate $ P $ 가 주어졌을 때, 과거의 대화 내용을 기반으로 object value $ O $ 에 대한 분포를 추정하게 된다. 과거 대화가 $ N $ 개의 utterance ($U_1, U_2, ..., U_N$)는 각각 $ M $ 개의 단어로 구성되므로, $ U_i = [U_{i,1}, U_{i,2}, ..., U_{i,M} ] $ 으로 표현할 수 있다. 각 단어 $ U_{i,m} $ 은 d 차원의 임베딩으로 나타낸다.
HAM은 총 3개의 함수로 이루어진다.
$ f_{utter} $ 함수를 통해서 $ R^{utter}_n $ 이라는 representation을 생성한다. 함수는 n번째 utterance를 입력으로 한다.
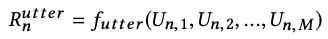
$ f_{subj} $ 는 subject representation인 $ R^{subj} $ 를 생성한다. 해당 함수는 $ f_{utter} $ 로 행성한 모든 utterance representation을 입력으로 받는다.
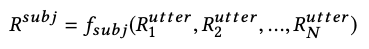
$ f_{obj} $ 는 object values $ O $ 에 대해서 확률분포를 계산한다.

HAMs 는 총 4개의 HAM들로 구성된다 : $ HAM_{avg}, HAM_{2attn}, HAM_{CNN}, HAM_{CNN-attn} $
$ HAM_{avg} $ : 모든 입력의 단순한 평균값을 구하는 함수([식-4])를 $ f_{utter}, f_{subj} $ 로 사용한다.$ f_{obj} $ 는 [식-5]를 사용한다.


$ HAM_{2attn} $ : utterance representation과 subject representation은 attention-weighted average를 이용해서 구하게 된다. ([식-5]) Attention weight $ a_i $ 를 곱해주게 된다.
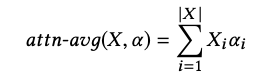
각 attention weight $ w_i $ 는 [식-6] 과 같이 구할 수 있다.

마지막으로 utterance 에 대한 representation $ R^{utter}_n $ 과 subject representation $ R^{subj}_n $ 을 두하고 softmax 함수를 통해서 마지막 확률분포를 구하게 된다. ([식-7])

$ HAM_{CNN} $ : 각 utterance 를 BoW(bag-of-words) 로 취급해서 n-gram을 고려한다. Yoon Kim 님의 CNN classifier를 그대로 사용했다. 각 utterance에 대해서 k-max pooling 을 수행해서 utterance represenatation을 생성하고, 각 utterance representation 들에 대해서 k-max pooling 을 수행해서 subject representation을 생성한다. 마지막으로 softmax 함수를 통해서 확률분포를 구하게 된다.
$ HAM_{CNN-attn} $ : $ HAM_{CNN} $ 에 attention 기법을 추가해서 utterance representation과 subject representation을 합치게 된다.
학습 과정 : 모든 $ HAM $ 은 gradient descent 를 이용해서 cross-entropy 값을 최소화하기 위해 학습된다. Adam optimizer를 이용해서 학습을 진행하고 L2 weight decay 를 적용한다.
하이퍼파라미터 : 모든 하이퍼파라미터는 ten-fold cross-validation을 사용한 grid search 를 통해 정했다. 300 차원의 word2vec 임베딩을 사용했고, 각 주인공의 utterance의 길이를 $ N = 40 $ 으로, 각 utterance의 길이를 $ M = 40 $ 으로 제한했다. 길이가 더 긴 경우 truncate을 하고, 짧은 경우 zero padding을 수행했다.
- $ HAM_{avg} $ : 은닉층은 100차원, 30 에포크 동안 학습을 진행했다.
- $ HAM_{CNN} $ : 크기 2의 178개의 커널을 사용하고 k= 5 인 k-max pooling을 수행했다. 40에포크 동안 학습했다.
- $ HAM_{2attn} $ : 150 에포크 동안 학습했다.
- $ HAM_{CNN_attn} $ : 크기 2의 128개의 커널로 50 에포크 동안 학습을 진행했다.
# 데이터셋
MovieChAtt dataset : Cornell movie-Dialogs Corpus 에서 영화의 주인공들과 주인공들의 대사를 추출했다. 등장하는 주인공 중 대사가 20문장 이하인 주인공은 제외되었다. Stop word와 가장 흔한 1000개의 이름, 4개 이상의 영화에서 공통적으로 나타나지 않는 단어들은 제외했다. (특정한 영화에 맞게 학습되는 것을 망지하도록 다양한 영화에 골고루 나오는 단어들만 사용했다.) IMDb 를 사용해서 사용자의 나이와 성별을 추출했다. 총 1,963명의 성별을 부여한 주인공과 4,548명의 나이를 부여한 주인공들을 추출했다. 나이는 0~13세를 child, 14~24세를 teenager, 24~45세를 adult, 46~65세를 middle-aged, 마지막으로 66~100세를 senior로 분류했다. 나이대에 대한 주인공들의 분포는 불균형했는데, adult 분야에 해당하는 주인공들이 58.7%로 가장 많았고, child 로 분류된 주인공들이 1.7%로 제일 적었다. 다음으로는 주인공의 직업(profession)에 대한 분류를 헀다. 꼭 직업이 아니더라도, child나 criminal 같은 표현도 직접에 추가했다. 결과적으로 1,405개의 주인공을 분류할 수 있었고 총 43개으 profession을 구할 수 있었다. 해당 데이터도 불균형이 있는데, 많은 주인공이 criminal 이거나 detective로 분류가 되었고, waiter나 engineer 등의 직업은 적게 분류되었다.
PersonaChat dataset : PersonaChat corpus를 기반으로 하고있다. 해당 데이터셋은 두 사람이 대화하는 내용을 담은 데이터셋인데, 한가지 다른 점은 대화에 참여하는 두 사람의 persona를 5문장 정도로 정의하고 있다는 점이다. 해당 데이터셋을 기반으로 직업(profession)과 성별을 추출했다. 또한 대화에 참여하는 사람의 familty status(single/not single)도 함께 추출했다. 결과적으로 1,147명에 대한 직업, 1,316명의 성별 정보, 2,302명의 family status 를 추출할 수 있었다.

Reddit dataset : imma (특정한 사람에게 질문하는 방식) 와 askreddit (일반적인 대화) 에서 데이터를 추출해서 사용했다.20~100개의 단어로 구성된 20~100개의 연속적인 대화인 경우에만 데이터셋으로 사용했다. 실제 사람의 대화와 유사한 것만 사용하기 위해 각 대화를 평가했다.
전체 데이터셋의 특이사항으로는, MovieChAtt에서는 family status를 고려하지 않았고, PersonaChat에서는 나이를 고려하지 않았다. 또한, 실생활에서는 다양한 정답(예를들어, 한 사람이 다양한 직업을 보유할 수 있다.)이 있을 수 있다는 점을 고려하지 못했다.
실험 환경 : MovieChAtt과 PersonaChat을 학습데이터(90%)와 테스트 데이터(10%)로 구분했다. Family status나 성별같이 2개의 보기 중 정하는 문제의 경우 각 클래스에 속하는 데이터의 수를 조절했다. 나이와 직업과 같이 다양한 레이블이 존재하는 경우 downsampling을 수행해서 불균형을 어느정도 해소할 수 있었다. 그래도 전체 데이터셋을 어느정도 bias를 보유하고 있다는 것을 고려해야 한다.
평가 방식 : binary classification에 대해서는 accuracy로 모델의 성능을 평가하게 된다. multi-value classification의 경우, accuracy 만으로 성능 평가하는 것은 부족하기 때문에 다른 방식들을 사용한다. 한가지 방식으로는 Mean Reciprocal Rank (MRR) 이라는 방식이다. 해당 방식은 정답이 전체 보기의 순위 중 몇 번째 순위로 구분되었는지를 확인하고, 전체 순위의 평균으로 평가를 한다. 추가적으로 macro MRR의 경우 평균을 내기 전에 reciprocal rank를 계산하고, micro MRR의 경우 전체 reciprocal rank에 대해서 평균을 낸다. 다른 평가 방식으로는 Area under thr ROC curve (AUROC) 라는 방식이다. 해당 방식은 true positive rate과 false positive rate을 이용해서 평가를 수행한다.
# Baseline
# 실험 결과

실험 결과인 [표-2]를 보면 HAMs 가 모든 basline의 성능을 뛰어넘는다는 것을 확인할 수 있다. HAM과 N-GrAM 의 결과를 비교해보면, word n-gram을 사용하는 것보다는 woed embedding을 사용하는 것이 더 효과적이라는 것을 확인할 수 있다. 평균적으로 $ HAM_{avg} $ 가 가장 좋지 않은 성능을 제공하는데, 이것은 단순히 전체 표현의 평균을 내는 것은 성능에 도움이 되지 않는다는 것으로 해석할 수 있다. $ HAM_{CNN} $ 이 평균적으로 $ HAM_{CNN_attn} $ 보다 안좋은 성능을 제공한다는 것도 확인할 수 있다. 모든 HAM 들에 대해서 PersonaChat에서의 성능 차이가 작다는 것을 확인할 수 있는데, 이것을 해당 데이터셋을 구성하는 대화들이 조금은 더 다순하기 때문이라고 이해할 수 있다. (대화를 생성할 때, 자신의 persona를 나타내기 위한 대화를 진행해야만 하는 환경, 상대적으로 더 짧고 단순한 문장들로 구성되어 있다는 한계, persona로 기술된 문장들이 실제 대화에서 종종 사용된다는 문제)

Word embedding의 영향 : word embedding의 영향을 확인하기 위해 다음과 같은 단어 임베딩을 사용했다.
- Google New corpus로 학습한 word2vec
- Reddit dataset으로 학습한 word2vec
- Common crawl 데이터셋으로 학습한 GloVe
- Twitter 데이터셋으로 학습한 GloVe
- WMT News 데이터셋으로 학습한 ELMo
임베딩의 성능을 비교하기 위해 가장 성능이 좋았던 $ HAM_{CNN-attn} $ 과 $ HAM_{2attn} $ 을 사용해서 실험을 진행했다. 실험 결과 셀제로 큰 성능의 차이가 없었고, 어떤 임베딩을 사용하는가는 전체적인 성능에 크게 영향이 없다는 것을 확인할 수 있었다.
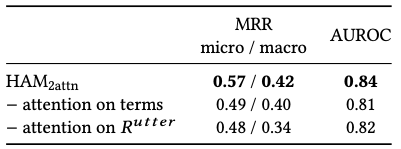
Ablation study : HAM 을 구성하는 각 부분들의 영향을 측정하기 위해 ablation study 를 진행했다. $ HAM_{attn} $ 모델에서 각 utterance representation을 생성하기 위해 사용된 attention과 전체 subject representation을 생성하기 위햇 사용한 attention을 각각 제거했을 때의 성능을 비교했다. 결과는 [표-4]와 같고 attention을 중요한 역할을 한다는 것을 확인할 수 있다.


$ HAM_{CNN_attn} $ 의 성능이 종종 $ HAM_{2attn} $ 의 성능을 넘어설 때도 있지만, $ HAM_{2attn} $ 의 결과는 어느정도 해석이 가능하다는 점에서 $ HAM_{2attn} $ 의 attention weight을 시각화해보았다. $ HAM_{2attn} $ 이 해당 결과를 예측하기 위해 어떠한 단어들에 높은 attention을 가지고 있는지 시각화했다. ([그림-1], [그림-2]) 분류하려는 답(military personnel, child, female, married) 과 관련성이 높은 단어들(guard, mommy, boyfriend, husbamd) 에 높은 attention weight을 보유한 것을 확인할 수 있다.

직업을 분류하기 위해서 높은 attention을 보유한 단어(significant word) 를 뽑아봤다([표-5]). 실제 직업과 직접적인 관련이 있어서 유추하기 쉬운 직업(위)들이 있는 반면, 직접과 거의 관련성이 없거나, 특정 영화에 맞게 학습된 경우들(아래)도 발견되었다.

Transfer learning : MovieChAtt과 PersonaChat의 데이터에 대해서 학습한 모델을 Reddit 데이터셋에 대해서 검증해봤다. ([표-6]) PersonaChat에 대한 결과는 낮게 나왔지만, movieChAtt에 대한 성능은 어느정도 비슷하게 나온것을 확인할 수 있다.

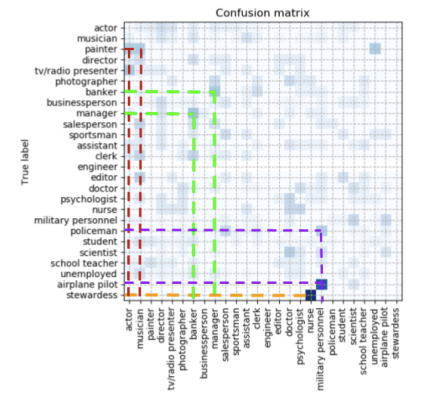
Misclassification study : 직업(profession)을 잘못 분류한 경우(misclassification) 를 시각화했다. ([그림-3], [그림-4]) 우리가 납득할 수 있을 만한 misclassification 들이 발생했다. 예를들어, policemen이 detective, special agent로 잘못 분류되는 겨우, scientist가 astronaut으로 잘못 분류되는 등의 경우가 있다.
# 참고 논문
- A Knowledge-Grounded Neural Conversation Model : general purpose agent (1)
- A Persona-Based Neural Conversation Model. : general purpose agent (2) (리뷰)
- A Neural Network Approach to Context-Sensitive Generation of Conversational Responses. : general purpose agent (3)
- Personalizing Dialogue Agents: I have a dog, do you have pets too? : explicit personal attribute를 사용하는 방식 (리뷰)
- Age and Gender Classification of Tweets Using Convolutional Neural Networks. : social media를 통해서 사용자의 특징을 찾아내는 방식 (1) (baseline)
- Privacy on Reddit? Towards Large-scale User Classification. : social media를 통해서 사용자의 특징을 찾아내는 방식 (2)
- Analyzing Biases in Human Perception of User Age and Gender from Text. : social media를 통해서 사용자의 특징을 찾아내는 방식 (3)
- Demographic Inference on Twitter using Recursive Neural Networks : social media를 통해서 사용자의 특징을 찾아내는 방식 (4)
- Twitter Demographic Classification Using Deep Multi-modal Multi-task Learning : social media를 통해서 사용자의 특징을 찾아내는 방식 (5)
- An analysis of the user occupational class through Twitter content. : social media를 통해서 사용자의 특징을 찾아내는 방식 (6) (baseline)
- N-GrAM: New Groningen Author-profiling Model— Notebook for PAN at CLEF 2017. : author profiling, (baseline)
- Hierarchical Recurrent Attention Network for Response Generation. : neural conversational model (1)
- An Attentional Neural Conversation Model with Improved Specificity. : neural conversational model (2)
- Adam: A method for stochastic optimization. : Adam optimizer
- Distributed Representations of Words and Phrases and Their Compositionality. : word2vec
- GloVe: Global Vectors for Word Representation. : GloVe (리뷰)
- Deep Contextualized Word Representations. : ELMo (리뷰)




댓글