
<딥 러닝을 이용한 자연어 처리 입문>을 읽고 간단하게 정리한 내용이다.
이번 글에서는 통계적 언어 모델(SLM)을 다뤄본다.
추가적으로 automated evaluation metric 중 하나인 perplexity에 대해서도 알아본다.
# 언어 모델 (Language Model)
Language model (LM) 은 단어 시퀸스에 확률을 할당하는 문제이다. 단어에 확률을 할당해서 가장 자연스러운 단어 시퀸스를 찾아내는 것을 목표로 한다. 시퀸스를 구성하는 이전 단어들이 주어지면, 그 단어들을 기반으로 다음 단어를 예측하게 된다. LM 을 적용할 수 있는 분야들로는 기계번역(machine translation, MT), 오타 교정, 음성 인식 등이 있다. LM은 크게 통계를 이용하는 방법과 인공 신경망을 이용하는 방법으로 구분할 수 있다.
전체 단어의 시퀸스를 $ W = (w_1, w_2, ..., w_n) $ 이라고 할 때, 전체 단어의 확률은 $ p(W) = p(w_1, w_2, ..., w_n) $ 으로 나타낼 수 있다.다음에 등장하는 단어의 확률을 $ p(w_n|w_1, ..., w_{n-1}) $ 로 나타낼 수 있으므로, 전체 단어 시퀸스의 확률은 $ \prod_{i=1}^n p(w_i|w_1, ..., w_{i-1}) $ 로 정의할 수 있다.
# 통계적 언어 모델 (SLM)
Bayes rule에 의해 전체 단어 시퀸스의 확률은 $ p(w_1, ..., w_n) = p(w_1)p(w_2|w_1)...p(w_n|w_1, ..., w_{n-1}) $ 이라고 정의할 수 있다. 이 식에서 각 단어들의 조건부 확률을 어떻게 구하느냐에 따라서 count기반의 접근과 N-gram 기반의 접근으로 구분할 수 있다.
count 기반의 접근 : 단순히 시퀸스를 구성하는 단어들이 몇 번 등장하는지를 count 해서 count 값을 기반으로 조건부 확률을 구하는 방법이다. 예를 들어, "An adorable little boy" 라는 시퀸스가 현재 주어졌을 때, 다음 단어가 "is" 일 확률 $ p(is|An adorable little boy) $ 를 구하는 방법은 [식-1]과 같다.
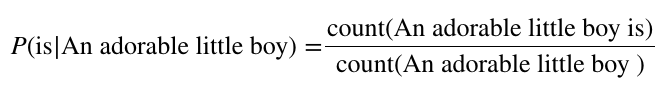
이렇게 단순히 count 기반으로 하는 경우 희소문제(sparsity problem)이 발생할 수 있다. count기반으로 LM을 구축하는 경우, 정말 많은 양의 데이터가 필요하다. 데이터가 부족한 경우, 어떠한 경우에 대해서 count가 0인 경우가 발생한다. 예를 들어, [식-1]에서 구하고자 하는 "An adorable little boy is" 라는 단어의 시퀸스는 실제로 충분히 나타날 가능성이 있는 문장이다. 하자민, LM을 구축하는 과정에서 위와 같은 시퀸스가 한 번도 나타나지 않은 경우, count 는 0이 될 것이고, 그러면 "An adorable little boy" 라는 단어 시퀸스 다음으로 "is" 라는 단어가 올 확률을 0이 된다. 더 심각한 경우 "An adorable little boy" 라는 시퀸스 자체가 count 된 경우가 없는 상황도 충분히 발생할 수 있다. 이런 문제들은 0이라는 확률이 나오지 않도록 모든 단어들에 아주 작은 확률을 부여하는 smoothing 기법이나, count가 0 이면 한 단어를 제외하고 다시 count를 적용하는 backing-off 방식 등을 적용할 수 있다.
N-gram 기반의 접근 : N-gram을 이용하면, 전체 단어의 시퀸스를 고려하는 것이 아니라, 일부만 고려하게 된다. 기존의 count 기반 방식은 계산하고 싶은 문장이 길어질수록 corpus에서 해당 문장이 존재할 가능성이 낮아지고, 그만큼 희소 문제가 심해졌었다. N-gram 방식을 사용하면 참고하는 단어를 줄일 수 있다. 현재 예측하려고 하는 단어는 해당 단어와 가장 가까이에 있는 단어들의 영향을 가장 많이 받는다는 가정 하에, 현재 예측하려는 단어와 가장 가까이에 있는 (n-1) 개의 단어만 고려한다. 현재 단어만 고려하는 경우 unigram, 앞에 1개의 단어만 고려하는 경우 bigram, 2개의 단어를 고려하면 trigram, 3개의 단어를 고려하면 4-gram 이라고 부른다. 하지만 어디까지나 동일하게 count기반의 방식이기 때문에 희소 문제는 피할 수 없다. 희소 문제는 n의 크기와 반비례하는데(trade-off 관계) n 이 커지면 더 많은 문맥을 고려하기 때문에 성능이 좋아지는 반면 희소 문제가 발생할 가능성이 커지기도 한다. 그렇기에 n-gram에서 n은 최대 5 정도로 잡는다.
# Perplexity
LM의 성능을 평가하는 방법 중 하나로 perplexity(PPL)를 들 수 있다. PPL은 단어의 수로 정규화된 확률의 역수로 구할 수 있다. LM에 대해서 PPL의 값이 낮을수록 좋은 성능을 낸다고 할 수 있다. 하지만 어디까지나 데이터 상에서 좋은 성능을 낸다는 뜻이지, 실제로 사람이 봤을 땐 좋지 않은 결과일 수 도 있다. 실제로 구하는 식은 [식-2]와 같다.

[식-2]를 구성하는 분모에 chain rule을 적용시키면 [식-3]과 같이 풀어서 쓸 수 있다.

PPL은 분기계수(barnching factor)의 일종이라고 볼 수 있다. 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 확인할 수 있다. 예를 들어, PPL=10 이면, 각 timestep마다 평균적으로 10개의 단어들을 고려한다고 이해할 수 있다.
'필기 노트 > 자연어 처리 입문' 카테고리의 다른 글
| [자연어 처리 입문] 순환 신경망 (Recurrent Neural Network) (0) | 2021.01.07 |
|---|---|
| [자연어 처리 입문] 토픽 모델링 (Topic Modeling) (1) | 2021.01.05 |
| [자연어 처리 입문] 문서 유사도 (Document similarity) (0) | 2020.12.31 |
| [자연어 처리 입문] Count-based word representation (BoW, DTM, TF-IDF) (0) | 2020.12.31 |
| [자연어 처리 입문] 데이터 전처리 (text preprocessing) (0) | 2020.12.28 |




댓글