
Word2vec에 대한 논문이다.
논문의 본문은 여기에서 확인할 수 있다.
1. Introduction
기존의 NLP 에서는 모든 단어를 독립적인 atomic 한 요소로 취급했다. 그렇기 때문에 단어들 사이의 유사성을 파악하는 것이 불가능했다. 반면에, 단순하고 robust하다는 등 다양한 장점들 덕분에 해당 방식을 계속 사용해왔다. 하지만, 이런 단순한 방식에는 많은 한계점이 존재한다. 최근 머신 러닝의 발전으로 우리는 조금 더 복잠한 모델을 큰 데이터셋을 이용해 학습할 수 있었고, 복잡한 모델들은 단순한 모델의 성능을 뛰어넘을 수 있었다. 가장 성공적으로 사용된 방식은 단어를 distributed representation으로 표현하는 방식이라고 할 수 있다.
이번 논문은 큰 데이터셋을 이용해서 high-quality의 단어 벡터를 생성하는 방식에 대해서 제안한다. 기존에 사용되던 구조들은 큰 데이터셋에 대해서 학습할 수 없었고, 벡터의 크기도 50-100정도 밖에 사용하지 못했다. 이번 논문에서는 높은 벡터 연산 정확도를 제공할 수 있는 벡터를 학습하는 구조에 대해서 제안한다. Neural Network Language Model(NNLM)은 기존에 제안된 구조로서, 단어 벡터를 학습할 수 있다. NNLM은 하나의 hidden layer 만 이용해서 전체 학습을 가능하게 한다.
2. Model Architectures
다양한 구조의 성능을 비교하기 위해서 computational complexity 를 전체 모델을 학습하기 위해 필요한 파라미터의 수로 정의한다. 우리는 정확도를 높이면서 computational complexity를 낮추려고 한다. Training complexity O 는 다음과 같이 정의한다.

- E : 학습 epoch의 수
- T : 전체 training set의 단어 수
- Q : 각 모델에 대해서 별도로 정의된다.
2.1 Feedforward Neural Net Language Model (NNLM)
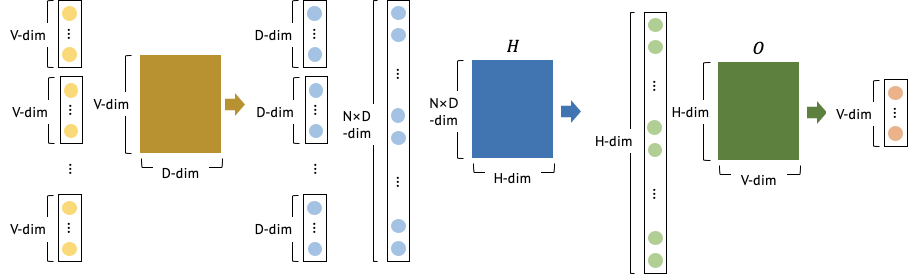
Feedforward Neural Net Language Model 도 제안되었었다. (해당 논문에 대한 정리를 보려면 여기) Input, projection, hidden, output layer 로 구성되어 있다. Input layer에서는 N개의 선행 단어들이 one-hot-encoding으로 주어진다. 전체 vocabulary의 크기가 V 인 경우, V 크기의 벡터가 주어진다. N 개의 input은 V×D 크기의 projeciton matrix에 의해 각각 D-차원으로 출력되고, 해당 출력은 N×D의 projeciton layer에 출력된다. projection layer의 값은 N×D×H 크기의 matrix 와의 연산을 통해서 N×H 의 출력을 생성하고, 해당 출력을 H×V의 출력층을 통해 V-차원의 벡터를 출력한다. 해당 결과는 softmax 함수를 통해 확률 분포로 제공되고, 정답으로 제공된 단어의 인덱스와 가까워지도록 학습된다. 보통 N = 10, D = 500~200, H = 500~1000 정도의 값으로 지정한다.
Computational complexity 는 다음과 같다.
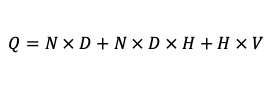
가장 큰 비용을 차지하는 부분은 H×V 이지만, hierarchical softmax 를 사용하면 V의 값을 logV 까지 줄일 수 있기 때문에, H×V 는 H×logV 의 크기로 줄일 수 있다. (hierarchical softmax에 대한 내용은 다음에 정리하도록 하겠다.) 위와 같은 방식으로 비용을 줄이게 된다면, 전체 비용 중 가장 큰 부분은 차지하는 것은 N×D×V 라고 할 수 있다.
2.2 Recurrent Neural Net Language Model (RNNLM)

Recurrent Neural Net Language Model (RNNLM)은 NNLM의 한계를 극복하기 위해서 생겨났다. RNNLM에서는 입력의 크기를 제한하지 않고 입력받아서 사용할 수 있다. 이론적으로 RNN은 더 복잡한 표현을 학습할 수 있다. 또한, Hidden layer를 자기 자신에게 연결시켜 short-term memory의 기능도 보유하고 있다. Word representation 의 D-차원이 H-차원가 일치하도록 했을때, Computational complexity는 다음과 같다.

NNLM과 동일하게, [식-3]에서 가장 큰 비용을 차지하는 것은 H×V 이지만, 동일하게 H×logV 까지 줄일 수 있다. 그렇다면, 가장 큰 비용을 차지하는 부분은 H×H 가 될 것이다.
2.3 Parallel Training of Neural Networks
큰 규모의 데이터를 다루기 위해서 DistBelief 라는 large-scale distributed framework를 사용했다. 해당 프레임워크는 동일한 모델의 다양한 복사본을 생성해서 동시에 실행시키고, 파라미터는 한 개의 중앙 서버에서 처리한다. 병렬처리 과정에서는 mini-batch asynchronous gradient descent 를 사용했고, Adagrad라는 방식을 사용했다.
3. New Log-linear Models
이 섹션에서는 computational complexity를 최소화하면서 distributed representation을 학습하기 위한 두가지 모델 구조를 제안한다.
논문을 처음 읽어보고 간략하게 정리한 내용이다. 참고만 하세요.
1. Introduction
1.2 Goal of the Paper
- 성능이 좋은 word vector를 학습할 수 있는 기술을 소개한다.
- word vector 중 의미가 유사한 단어들은 가까이 위치하고 있을 뿐만 아니라, multiple degrees of similarity 를 보유하고 있다.
- word vector 사이의 연산도 가능하다 : vector("King") - vector("Man") + vector("Woman") = vector("Queen")
- 이번 논문에서는 word vector의 정확도를 최대화할 수 있는 모델을 소개한다.
1.2 Previous Work
- 단어를 vector로 나타내는 데에는 긴 역사가 있다.
- Neural Network Language Model (NNLM) : linear projection을 하는 feedforward NN
- NNLM의 새로운 구조
- 한 개의 hidden layer 를 보유하는 NN을 사용해서 word vector를 학습
- 학습된 결과를 이용해서 NNLM을 학습시킨다(?)
- word vector를 이용해서 많은 NLP 문제들에 적용할 수 있다는 것을 알 수 있었다.
- 하지만, 기존의 방식들은 계산 비용이 매우 크다.(computationally expensive)
2. Model Architectures
- LDA, LSA 등 연속적인 단어표현을 예측하는 모델들이 존재한다.
- 이번 논문에서는 distributed representation 을 사용한다.
- LSA 는 linear regularities 를 유지하는 성능이 떨어진다.
- vector("King") - vector("Man") + vector("Woman") = vector("Queen") : 이러한 연산을 하는 성능
- LDA 는 큰 데이터셋에 대해서 계산하는 비용이 매우 크다.
- LSA 는 linear regularities 를 유지하는 성능이 떨어진다.
- 전체적인 성능을 끌어 올리면서, 연산 비용을 최소화한다.
- 이번 논문에서 제안한 training complexity O = E × T × Q
- E : 학습 epoch 수 (보통 3-50)
- T : training set에 있는 단어의 수 (~ 1,000,000,000개)
- Q : 각 모델에서 별도로 정의한다.
- compuatational complexity 는 학습된 전체 모델을 구성하는 파라미터의 수로 정의한다.
- SGD와 backpropagation 으로 학습을 진행한다.
2.1 Feedforward Neural Net Language Model (NNLM)
- input, projection, hidden, output layer로 구성된다.
- input layer
- N 개의 이전 단어들이 1-of-V coding(one-hot-vector)으로 인코딩된다. (V 는 전체 단어의 수)
- 보통 N = 10 으로 지정
- projection matrix를 통해 input이 projection layer로 전달된다.
- projection layer
- N × D dimensionality
- 상대적으로 저렴한 비용의 연산이다.
- D = 500 ~ 2000
- hidden layer
- projection layer와 hidden layer 사이의 연산에서 상대적으로 큰 비용이 발생한다.
- hidden layer size H = 500 ~ 1000
- output layer
- V 차원의 결과를 제공한다.
- 계산 비용 computational complexity Q = N × D + N × D × H + H × V
- 가장 큰 비용을 차지하는 부분 : H × V
- hierarchical softmax 를 사용하면 비용이 log(V) 까지 줄어들 수 있다.
- 비용을 위와 같이 줄여도 N × D × H 가 다음으로 큰 비용을 차지한다.
- 가장 큰 비용을 차지하는 부분 : H × V
2.2 Recurrent Neural Net Language Model (RNNLM)
- Feedforward NN의 몇 가지 단점을 극복하고자 사용 : 입력의 길이를 명시하지 않아도 된다.
- input, hidden, output layer 로 구성된다.
- hidden layer를 사용해서 short term memory를 유지할 수 있도록 한다.
- 이전 hidden layer의 정보와 새로운 input에 대해서 새로운 hidden layer를 생성하기 때문에, 과거의 정보를 어느정도 유지할 수 있다.
- hidden layer를 사용해서 short term memory를 유지할 수 있도록 한다.
- 계산 비용 computational complexity Q = H × H + H × V
- H × V 는 H × log(V) 로 축소될 수 있다. (hierarchical softmax)
- 대부분의 비용은 H × H 에서 온다.
2.3 Parallel Training of Neural Networks
- DistBelief : large-scale distributed framework
- 동일한 모델을 병렬처리 할 수 있다.
- gradient update를 중앙 서버를 통해서 하게 된다. (모든 파라미터를 보유)
- Adagrad : mini-batch asynchronous gradient descent
- 해당 프레임워크를 사용하면 100개 이상의 서로 다른 CPU에서 동시에 학습이 가능하다.
3. New Log-linear Models
- 계산 비용을 최소화하면서 distributed word vector를 학습할 수 있는 2가지 모델을 제안
- NNLM, RNNLM에서는 대부분의 비용이 non-linear hidden layer에서 발생했다.
- 위의 방식만큼 정밀한 word vector가 아닐 수 있지만, 더 효율적으로 데이터를 처리할 수 있는 방법을 제공한다.
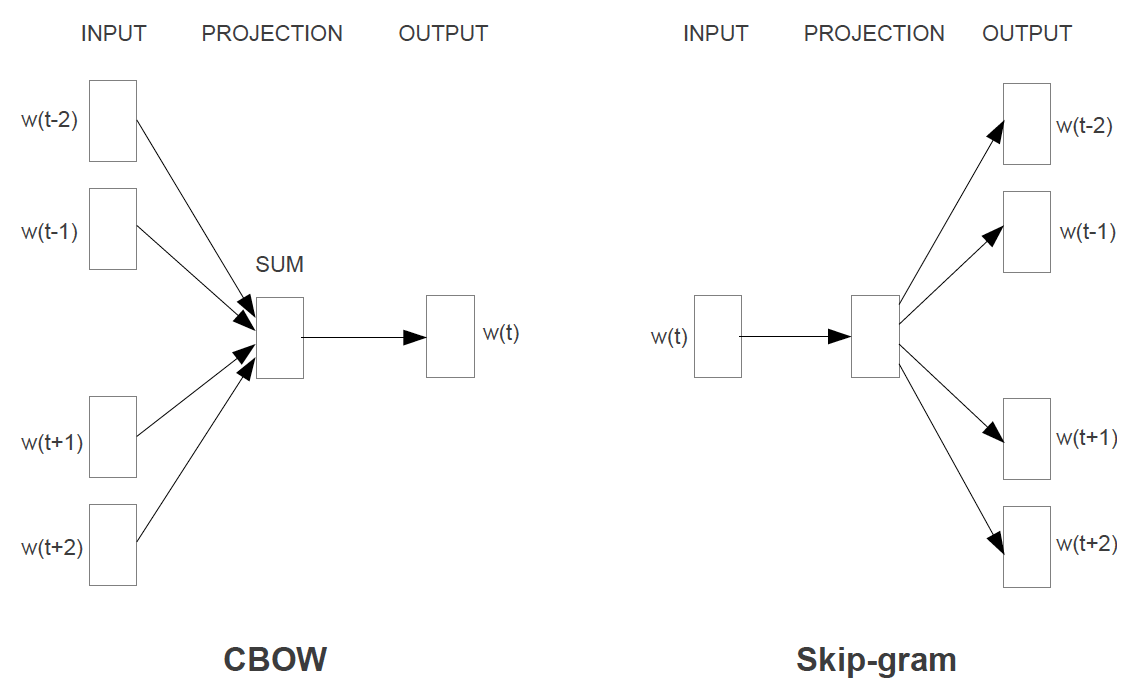
3.1 Continuous Bag-of-Words Model
- feedforward NNLM 과 유사하지만, non-linear hidden layer가 모두 제거되고 projection layer가 모든 단어들과 공유된다.
- 전체 word vector의 평균값을 사용하게 된다. = bag-of-words model
- 단어의 순서가 projection에 영향을 주지 않는다. (그냥 평균을 사용하기 때문에)
- 이래의 단어들도 사용한다.
- 4개의 과거 단어들과 4개의 미래 단어들을 입력으로 사용한다.
- 입력들을 이용해서 중간 단어를 classify 하는 것이 목표이다.
- 계산 비용 training complexity Q = N × D + D × log(V)
- 해당 모델을 CBOW 라고 부른다.
- 연속적인 context를 사용하기 때문이다.
3.2 Continuous Skip-gram Model
- CBOW와 다르게, 중간 단어를 이용해서 주변 단어를 예측하는 방식이다.
- 중간 단어를 log-linear classifier에 입력으로 제공한다.
- 현재 단어의 일정 범위 내에 있는 이전/이후의 단어를 예측한다.
- 범위를 증가시키면 word vector의 성능이 좋아지지만, 계산 비용이 증가한다.
- 또한, 현재 단어와 멀리 떨어진 단어는 해당 단어와 관련이 있을 가능성이 낮기 때문에, 낮은 weight를 제공한다.
- 계산 비용 training complexity Q = C × (D + D × log(V))
- C : 단어 사이의 최대 거리
- 이후 실험에서는 C = 10 을 사용한다.
4. Results
- word similarity
- big 와 biggest 의 관계처럼 small 에 대응하는 단어는 뭘까?
- vector("biggest") - vector("big") + vector("small") = vector("smallest")
- big 와 biggest 의 관계처럼 small 에 대응하는 단어는 뭘까?
- 고차원 벡터를 학습하면 단어들 사이의 semantic relationship을 학습할 수 있다.
- city-country 등의 관계를 학습할 수 있다.

4.1 Task Description
- Test set of 5 types of semantic questions, 9 types of syntactic questions.
- 8,869 semantic and 10,675 syntactic questions
- 수작업으로 유사한 단어들을 골라낸다.
- 2개의 단어를 짝을 지어서 큰 질문 리스트를 생성한다.
- 8,869 semantic and 10,675 syntactic questions
- 평가(evaluation)
- 예측한 결과 벡터에 가장 가까운 단어가 질문과 완벽하게 일치하는 경우 정답으로 처리한다.
- 100%의 정확도는 불가능하다는 뜻이다.
- 동의어는 오답으로 처리된다.
- 예측한 결과 벡터에 가장 가까운 단어가 질문과 완벽하게 일치하는 경우 정답으로 처리한다.
4.2 Maximization of Accuracy
- Google News 를 사용해서 word vector를 학습했다.
- 6B 개의 토큰으로 구성된다.
- 단어의 개수를 가장 자주 나타나는 100만개로 제한했다.

- 어느 순간 이후로 차원을 늘리거나, 학습 데이터를 주가하는 것으로는 나타나는 성능 향상은 적다.
- 그러므로, 성능 향상을 위해 차원을 늘림과 동시에 학습 데이터를 추가해야 한다.
4.3 Comparison of Model Architectures
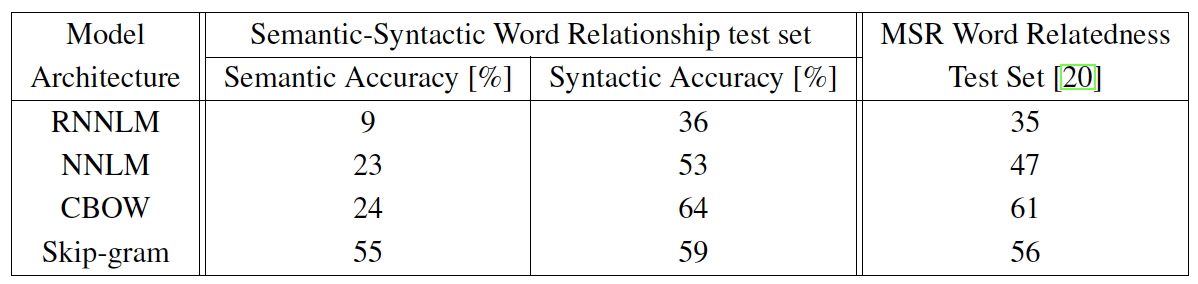
- 640 dimension의 word vector를 사용한 동일한 학습 데이터를 이용해서 서로 다른 모델 구조를 비교한다.
- 학습 데이터는 LDC 말뭉치들을 표함한다.
- 기존에 학습된 NNLM과 비교한다.
- 640 개의 hidden units
- DisBelief 병렬 처리를 통해 학습했다.
- 이전 8개의 단어를 입력으로 제공하는 방식으로 학습했다.
- 결과
- RNN은 syntactic 문제에 대해서 성능이 더 좋다.
- NNLM은 모든 항목에 대해서 RNNLM에 비해 성능이 좋다.
- CBOW는 NNLM에 비해 syntactic 성능은 좋지만 semantic 성능은 유사하다.
- Skip-gram은 CBOW에 비해 syntactic 성능은 조금 떨어지지만, semantic 성능은 모든 모델들에 비해서 좋다.

- 공개된 다른 word vector와 성능을 비교해봤다.
- Semantic-Syntactic Word Relationship test set 에 대한 성능을 비교했다.
- 비교에 사용된 CBOW 모델을 Google News에 대해서 하루 동안 학습되었고, Skip-gram 은 3일 정도 학습되었다.
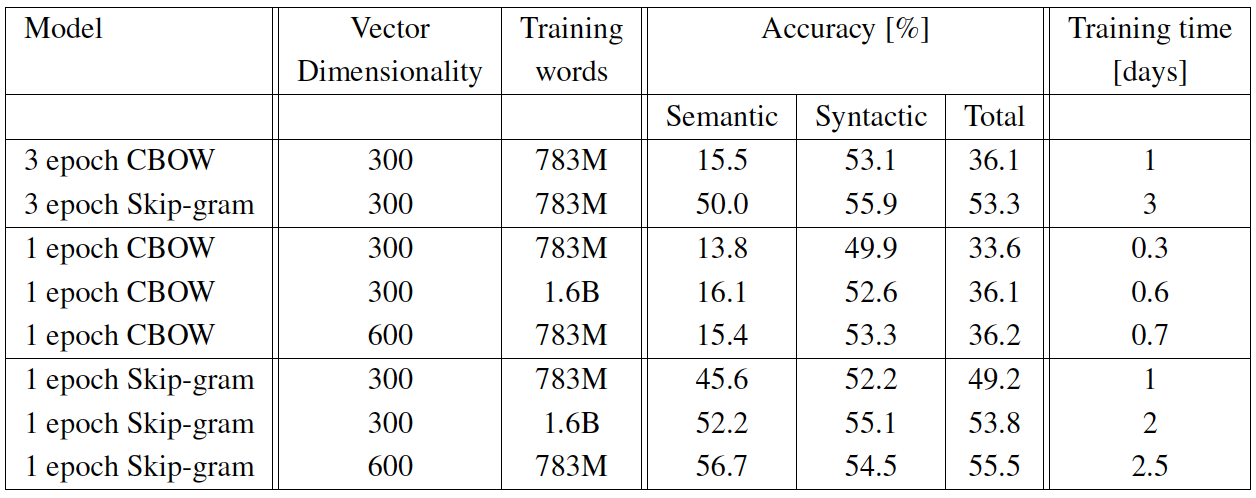
- 상대적으로 적은 데이터를 여러번의 epoch 를 통해 학습하는 것보다, 많은 데이터를 이용해 1번의 epoch만 학습하는 것이 더 좋은 성능을 제공한다는 것을 알 수 있었다.
4.4 Large Scale parallel Training of Models

- Google News 데이터에 대해 학습된 몇 개의 모델 통계를 제공한다.
- DistBelief를 사용해서 학습했으며, 50~100 개의 복제본을 생성해서 학습했다.
- CBOW 와 Skip-gram 의 CPU 사용량은 거의 비슷하다는 것을 알 수 있다.
- NNLM의 벡터 차원을 1000으로 사용하면 연산 시간이 너무 오래 걸려 100으로만 제한했다.
4.5 Microsoft Research Sentence Completion Challenge

- Microsoft Research Sentence Completion Challenge 는 하나의 단어가 없는 1,040의 문장으로 구성된다.
- 빈 단어에 알맞는 단어를 찾아내는 것이 목표이다.
- Skip-gram 구조를 적용시켜봤다.
- Skip-gram 만으로는 높은 성능을 제공하지 못한다.
- RNNLM과 함께 적용한 경우 58.9%라는 높은 성능을 제공했다.
5. Examples of the Learned Relationship

- 관계(relationship)는 다음과 같이 정의한다.
- 두 단어를 빼고 다른 단어에 대해서 더한 결과를 확인한다.
- Paris - France + Italy = Rome
- 두 단어를 빼고 다른 단어에 대해서 더한 결과를 확인한다.
- 더 큰 데이터셋에 대해서 학습을 진행한다면 더 좋은 성능을 낼 수 있다고 생각한다.
- out-of-list word를 찾아내는 문제에서도 word vector 가 사용될 수 있다.
- 전체 단어에 대한 평균 벡터를 구하고, 해당 벡터에서 가장 멀리 떨어진 word vector를 찾아내를 방식이다.
6. Conclusion
- 벡터 표현에 대한 성능을 다양한 모델을 이용해서 다양한 task에 대해서 측정했다.
- 단순한 구조로도 뛰어난 성능의 word vector를 학습할 수 있다는 것을 알 수 있었다.
- NNLM과 RNNLM과 비교해서
- 연산 비용이 매우 작기 때문에, 큰 차원의 큰 데이터셋에 대한 학습도 가능하다.
- SemEval-2012 Task 2에서 state-of-art 의 성능을 제공했다.




댓글