
한 단어($ c $)는 그 단어의 주위 단어에 의해서 뜻을 유추할 수 있다.

[그림-1]을 보면 center word 는 "banking" 이고, 해당 단어를 둘러싸고있는 context word 는 각각 "turning", "into", "crises", "as" 등으로 구성된다. Word2vec에서는 주변 단어 $ o $ 와 중간 단어 $ c $ 사이의 관계 $ P(O = o | C = c) $ 를 계산하려고 한다.
이 방법의 경우는 skip-gram 방식으로, 중간 단어가 주어졌을 때, 주번 단어를 예측하는 방식이다. 다른 방식으로는 Continuous bag-of-words (CBOW)가 있는데, 이 방식의 경우에는 주변 단어에 따라서 중간 단어를 예측하는 방식으로 학습이 진행된다.
해당 Conditional probability 는 [식-1]과 같이 계산하게 된다. 이 때, $ u_o $ 는 context word vector 를 상징하고, $ v_c $ 는 center word vector 를 상징한다. 파라미터를 구분하기 위해서 두 matrix $ U, V $ 로 구분해서 사용한다. $ U $ 의 모든 column 은 주변 단어(context word) 들로 구성되어 있고, $ V $ 의 모든 column 은 중간 단어 (center word) 들로 구성되어 있다.

Loss는 [식-2]와 같이 구할 수 있다. 다른 방식으로는 실제 답과 예측된 답 사이의 cross-entropy를 구하는 방식이 있다. 실제 답과 예측된 답은 동일한 길이의 벡터로 구성되어 있고, 한 벡터의 값은 $ c $ 가 context word 로 주어졌을 때, 해당 인덱스의 단어가 center word 가 될 확률을 나타낸다. 비슷한 맥락으로, 실제 답을 구성하는 벡터는 정답에 해당하는 인덱스의 값은 1(100% 이므로) 나머지는 모두 0인 one-hot-vector 로 구성된다.

# 문제


$ y_w $ 는 실제 답이 경우만 1이고 나머지는 모두 0이기 때문에, 실제 답인 값을 제외하고 모두 0이 된다. 그러므로 [식-3]이 참이 된다.





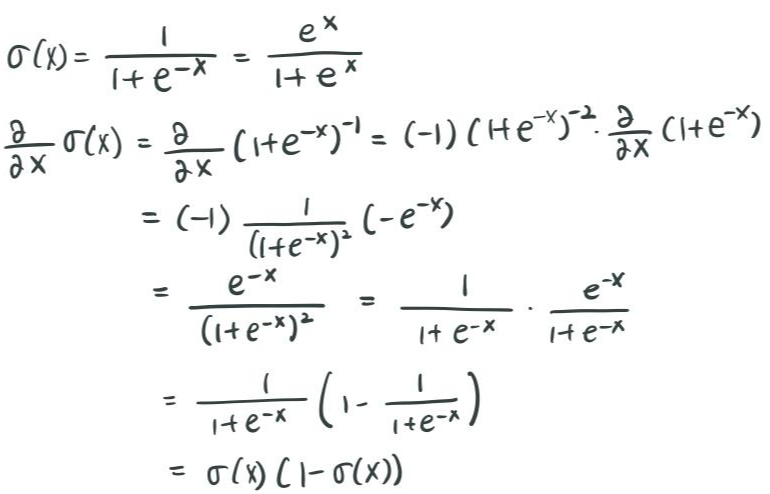



기존의 방식(naive-softmax) 보다 새로운 방식(negative sampling)의 성능이 더 좋은 이유 : naive softmax 같은 경우는 언제 vocabulary에 대해서 softmax 연산을 해야 한다는 문제가 있다. 전체 단어에 대해서 $ u^T_wv_c $ 의 연산 후 지수승을 하고 모두 더해줘야 하는데, 이러한 연산은 비용이 너무 많이 든다는 단점이 있다. 하지만, Negative sampling 의 경우, negative sample 몇 개만 뽑아서 해당 negative sample에 대한 loss function을 연산하기 때문에, 상대적으로 연산 비용이 적다는 장점이 있다.



실제 코딩을 해본 결과(식을 그대로 옮겨 적기만 하면 된다.), 다음과 같은 결과가 나왔다.

# 정리
word2vec의 skip-gram 방식에 대한 과제였다. 가운데 단어(center word) $ c $ 가 주어졌을 때, $ m $ 의 window size 내에 있는 주변 단어(context word) 가 나타날 conditional probability $ P(O = o | C = c) $ 를 구한다. Loss function을 $ -logP(O = o | C = c) $ 로 정의하고, loss를 최소화하도록 context word 와 center word의 벡터를 학습한다. Loss function을 최소화하기 위해서 Loss function을 각각 context word와 center word 에 대해서 미분한 값이 0이 되도록 벡터값을 수정해 나간다.
기존의 naive softmax는 전체 vocabulary에 대해서 softmax 연산을 수행해야 하는, 상대적으로 큰 연산 비용을 필요로 한다. 이러한 비용을 줄이기 위해 negative sampling 기법을 사용했다. Negative sampling 의 경우, context word 가 아닌 다른 단어들을 negative sample 로 지정해서, 해당 단어들에 대한 loss function의 값을 최소로 하도록 학습을 진행한다. Negative sample의 크기가 전체 vocabulary에 비해 상대적으로 적기 때문에, 연산 시간과 비용이 상대적으로 적게 든다는 장점이 있다.
Window size $ m $ 내에 있는 context word에 대해서 center word 와의 loss function을 계산한다. (naive softmax 이든, negative sampling 이든 상관없다.) Window 내에 있는 모든 단어에 대한 모든 loss를 합쳐서 해당 center word 에 대한 최종 loss 로 지정한다. 최종 loss 값을 0에 가깝게 하는 방향으로 학습을 진행한다.
'대학원 이야기 > CS224N : NLP with Deep Learning' 카테고리의 다른 글
| [CS224N] Assignment 4 (풀이 중) (0) | 2020.11.10 |
|---|---|
| [CS224N] Assignment 3 (0) | 2020.11.02 |
| [CS224N] Lecture 7 - Translation, Seq2Seq, Attention (수정 중) (0) | 2020.08.24 |
| [CS224N] Lecture 7 - Vanishing Gradients, Fancy RNNs (1) | 2020.08.23 |
| [CS224N] Lecture 6 - Language Models and RNNs (0) | 2020.08.23 |




댓글