
Open-domain 환경에서 discourse coherence(담화 응집성)을 유지하는 dialogue generation에 대한 내용이다.
논뭔의 원본은 여기에서 확인할 수 있다.
Discourse coherence(담화 응집성) 는 언어응 이해하고 생성하는데 매우 중요한 역할을 한다. 하지만 기존의 모델들은 세부적인 각각의 요소들에 대한 coherence 를 측정하는 기능만 제공한다. (lexical overlap, entity centering 등) 이번 논문에서는 discourse coherence에 대한 domain-independent neural model 을 제안한다. 크게 discriminative model과 generative model을 제안한다.
# Discriminative model
Discriminative model은 현재 문장 주위에 있는 문장들을 모두 positive example로 취급하고, 그 외에 임의로 대치되는 중간 문장들은 negative example로 취급한다. 현재 문장의 시퀸스를 $ C = (s_{n-L}, ..., s_{n-1}, s_n, s_{n+1}, ..., s_{n+L}) $ 이라고 정의한다. 이 때 $ L $ 은 전체 window size의 절만을 의미한다. 한 문장 $ s_n $ 은 $ M $개의 단어 $ w_{n1}, ..,. w_{nM} $ 으로 구성된다. 각 단어는 K 차원의 벡터 $ h_w $ 로 나타내고, 각 문장도 K 차원의 벡터 $ x_s $ 로 나타낸다. 결국 전체 문장 시퀸스 C 는 2L + 1 개의 문장으로 구성되고, 각 문장을 구성하는 벡터를 모두연결해서 (2L + 1 ) * K 차원의 벡터를 생성하게 된다. 각 문자의 벡터는 LSTM의 마지막 은닉층의 결과로 사용하게 된다. 이렇게 구한 문장의 벡터들을 모두 연결해서 새로운 모델의 입력으로 제공하고, 해당 모델을 가장 마지막 층에서 sigmoid 함수를 통해 해당 문장이 coherent한지 incoherent 한지 판단하게 된다.
해당 모델의 문제점은 크게 2가지가 존재한다. 첫 번째 문제점은 negative sampling을 이용하기 때문에 크기가 매우 큰 open-domain 환경에서 좋은 성능을 내지 못한다는 것다. Discriminative model은 작은 domain의 환경에서 더 좋은 성능을 내게 된다. 두 번째 문제는 discriminative model은 현재 중심 문장이 coherent 한지 여부를 판단할 수 있지, 새로운 문장을 생성하지는 못한다는 것이다. 이러한 문제를 해결하기 위해서 3가지의 generative model 들을 제안한다.
# Generative model
이전에 존재하는 문장들을 기반으로 다음 문장을 예측하는 seq2seq 모델을 변형한다. uni 방식에허는 연속적인 두 문장 $ s_i, s_{i+1} $ 에 대해서 likelihood를 [식-1]과 같이 계산할 수 있다. 해당 Likelihood를 이용해서 이전 문장을 기반으로 다음 문장을 생성해낼 수 있다.

Coherent context를 유지하기 위해서는 이전 문장은 물론 이후에 나타나는 문장도 함께 고려해야 한다. (bi 방식) 그러므로 forward model과 backward model을 각각 별개로 생성해서 [식-2]와 같이 사용한다. (각 모델을 서로 파라미터를 공유하지 않는다.)

[식-2]를 그대로 사용하게 되면, language modeling에서 그냥 높은 확률을 제공하는 문장들이 가장 확률이 높게 결과로 제공된다. 그렇기 때문에 language model의 영향을 상쇄시키기 위해서 lanauge model probability를 빼준다. ([식-3])
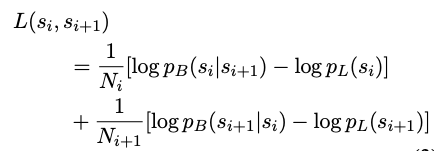
[식-1], [식-2], [식-3]은 모두 기존의 모든 텍스트가 주어진 경우 확률을 게산할 수 있다 하지만 generation을 하기 위해서는 위의 식에 필요한 정보들을 모두 가지고 있을 수 없다. (식을 계산하기 전에 예측을 수행해야 한다.) 이러한 문제를 해결하기 위해서 가장 일반적인 방법으로는 [식-1]을 이용해서 다음에 올 문장들을 N 개 예측하고, N개의 문장들을 [식-2], [식-3] 에 대해서 rerank를 수행한다. (N-best list 구축) 이런 방식에도 여전히 문제가 존재하는데, 가장 큰 문제로는 너무 앞에 있는 문장들의 영향력이 뒤로 갈수록 사라진다는 것이다. 그렇기에 해당 모델을 long-term discourse dependency를 다루는데 단점이 있다. 이러한 문제를 해결하기 위해서 전체 문장들의 의미(global meaning)을 파악해서 입력과 함께 제공할 수 있다. 이렇게 문제를 해결하는 방법으로는 크게 HMM-based topic model 과 end-to-end generative model을 제안한다.
# HMM-LDA-GM (Generative Model)
Markov topic model에서는 현재 topic은 이전에 context의 topic에 의존적이라고 정의한다. 그렇기에 현재 문장의 topic을 이전 문장의 topic에 기반해서 생성하게 된다. 이번 논문에서는 global context를 나타내는 벡터를 생성하기 위해서 HMM-LDA를 수행한다. 한 문장을 구성하는 단어들은 동일한 topic을 보유한다고 가정하고, 현재 문장의 topic은 이전 문장의 topic distribution에서 sampling 되었다고 가정한다. 현재 문장의 topic distribution 을 K 차원의 $ t_n $ 이라고 정의하고, topic representation matrix를 $ V $ 라고 정의한다. 현재 문장 $ s_n$ 에 대한 topic representation $ z_n $ 은 [식-4]와 같이 구하게 된다.

이렇게 해서 생성한 $ z_n $ 은 문장 $ s_n $ 을 생성하는 모든 과정에 영향을 주게 된다. ([식-5]) 조건부 확률로 모든 timestep 마다 $ z_n $ 이 고려되기 때문에, global information을 잃어버리는 기존의 문제점을 해결할 수 있다.

해당 방식에도 문제점이 있는데, LDA를 사용하는 경우 너무 일반적인 주제만 제공한다는 것이다.
# VLV-GM (Variational Latent Variable Generative Model)
VLV-GM도 동일하게 문장 $ s_n $ 이 global information을 포함하고 있는 벡터 $ z_n $ 의 영향으로 생성된다. $ z_n $ 은 이전 학습 데이터와 $ z_{n-1} $ 을 기반으로 생성하게 된다. 새로운 단어 $ w_{nt} $ 는 LSTM에 의해서 생성된 이전 출력 결과와 $ z_n $ 을 입력으로 받아서 생성하게 된다. Posterior 분포 $ p(z_n|s_1, ..., s_N) $ 을 예측하기 위해서 분포 $ q(z_n|s_1, ..., s_N) $ 을 사용한다. 결국 variational lower-bound를 최대화하는 방향으로 학습을 하게 된다. ([식-6])

SGD를 이용해서 encoder-decoder를 학습하고 gradient descent 를 이용해서 p와 q 사이의 KL-divergence 를 최소화하도록 학습한다.
# 실험 결과
Baseline : Entity Grid Model, Li and Hovy(2014) 방식(recursive model), Foltz et al. (1998) 방식 + GloVe, LDA vectors

Discriminative model에 대해서 sentence-pair ordering, full paragraph ordering reconstruction을 수행한다. 우선, task specific한 데이터셋에 대해서 수행해본다. 결과는 [표-1]과 같고, 오히려 generative model의 성능이 상대적으로 좋지 않게 나왔다는 것을 확인할 수 있다.

Open-domain : 더 큰 데이터셋인 wikipedia 데이터셋으로 동일한 실험을 진행했다. 실험 결과는 [표-2]와 같다. Discriminative model은 성능이 좋지 않은 것을 확인할 수 있고, generative model 들의 성능들이 매우 좋게 나온 것을 확인할 수 있다.

Open-domain pragaraph reconstruction : 더 나아가 문단을 구성하는 문장들의 순서를 결정하는 task를 수행해봤다. 결과는 [표-3]과 같다. Discriminative model은 해당 task를 수행할 수 없는 구성이기 때문에 제외했고 generative model 만 고려한다. 첫 번째 문장은 제공되고, 이후에 오는 가장 적합한 문장을 고르는데, beam size가 10인 beam search 를 수행했다. [표-2]에서의 binary classification과 거의 유사한 결과가 나왔다는 것을 확인할 수 있다.

Adversarial evaluation : generative model을 이용해서 multi-sentence generation을 수행한다. N 개의 문장을 생성하는데, 첫 번째 문장을 생성하기 위해서 처음에 제공된 문장을 사용하고, 두 번째문장을 생성하기 위해서는 기존에 제공된 문장과 첫 번째로 생성한 문장을 함께 사용한다. 3번 째 문장을 생성할 때도 동일하게 처음에 제공된 문장과 함께 첫 번재, 두 번째로 생성한 문장들을 모두 고려해서 생성하게 된다. Adversarial evaluation을 수행하는데, 단순하게 생각하면 그냥 binary classification 이다. 모델이 생성한 문장을 classifier가 사람이 생성했는지, 모델이 생성했는지 구분하게 되는데, 모델의 역할을 자신이 생성한 문장을 classifier가 사람이 생성했다고 분류하도록 하는 것이다. Adversarial Success(AdverSuc)을 [표-4]에 결과로 제공한다. 문장을 생성하는 횟수가 늘어날수록(N의 크기가 커질수록) 성능이 떨어지는 것을 확인할 수 있다.
# 추가적인 분석
해당 모델을 lexical coherence를 분석할 수 있다는 것을 확인했다. 두 번째 문장이 첫 번째 문장과 상관이 없는 경우 더 낮은 점수를 부여했다.

또한, Temporal relationship과 casual relationship을 학습했다는 것을 확인할 수 있었다.

# 참고 논문
- Modeling local coherence: An entity-based approach. : domain specific sentence-pair-ordering dataset, local coherence
- Generating sentences from a continuous space. : end-to-end dialogue model (1)
- Multiresolution recurrent neural networks: An application to dialogue response generation. : end-to-end dialogue model (2)
- A model of coherence based on distributed sentence representation. : discriminative model의 기반 모델
- Sequence to sequence learning with neural networks. : seq2seq (리뷰)
- Skip-thought vectors. : skip-thought vectors
- Neural machine translation by jointly learning to align and translate. : bahdanau attention (리뷰)
- Effective approaches to attentionbased neural machine translation. : Luong attention
- A diversity-promoting objective function for neural conversation models.
- Generating long and diverse responses with neural conversation models.
- Latent dirichlet allocation. : LDA
- A recurrent latent variable model for sequential data. : generating sentence from latent space
- Autoencoding variational bayes. : VAE (variational autoencoder)
- Stochastic backpropagation and approximate inference in deep generative models.
- A latent variable recurrent neural network for discourse relation language models.
- Learning stochastic recurrent networks.
- A model of coherence based on distributed sentence representation : sentence representation based on parse trees
- Glove: Global vectors for word representation. : GloVe (리뷰)
- Adversarial evaluation of dialogue models.




댓글