
Neural Machine Translation에서 자주 나타나지 않는 단어나, 처음보는 단어들에 대해서 대처하기 위해 subword model을 제안한다.
논문의 원본은 여기에서 볼 수 있다.
보통 Neural Machine Translation을 수행할 때 우리는 고정된 크기의 vocabulary 를 사용한다. 하지만, 번역하는 작업은 처음 보는 단어를 입력받을 수도 있고, 처음 보는 단어를 생성해야 하는 경우도 있기 때문에, open-vocabulary problem 이라고 볼 수 있다. 우리는 자주 등장하지 않는 단어나, 처음보는 단어에 대해서도 유연하게 번역 작업을 수행하는 것을 목표로 한다. 기존에 이렇게 자주 등장하지 않는 단어나 처음 보는 단어를 만났을 때, dictionary look-up을 통해서 해결하기도 했지만, 번역 문제의 특성상 모든 단어가 1대1로 대응되는 것이 아니기 때문에 실제 상황에서 좋은 성능을 내지 못했다. 이번 논문에서는 byte pair encoding을 기반으로 이러한 문제를 해결하는 방법에 대해서 이야기해본다.
기본적인 번역 성능을 비교하기 위해서 Bahdanau의 MT 모델과 유사한 구조를 사용한다. GRU를 사용해서 입력 $ x = (x_1, x_2, ..., x_m) $ 이 주어졌을 때, forward sequence와 backward sequence를 통해서 생성된 hidden state 2개를 연결해서 $ h_j $ 를 생성한다. 해당 벡터를 기반으로 정답 시퀸스 $ y = (y_1, ..., y_n) $ 을 예측하려고 하는데, 각 timestep의 결과는 이전 timestep의 결과와 decoder의 hidden state, 그리고 context vector의 영향을 받는다. (attention을 수행한 결과) 기존 방식은 단어 단위의 연산을 수행했지만, subword 단위로도 attention을 수행해본다. 기존 모델과 동일하게 1000 차원의 hidden layer를 사용하고, 620 차원의 embedding layer를 사용한다.
Subword model을 사용하면 기존 subword 들의 번역 결과를 기반으로, 처음 보거나 자주 등장하지 않는 단어들의 의미를 유추해서 번역을 진행할 수 있다. 예를 들어, English-German 데이터셋에서 자주 등장하지 않는 100개의 독일어 단어들 중 대부분은 subword model을 이용해서 번역이 가능하다는 것을 확인했다. 이러한 기능을 처음보는 단어들에도 적용하면, 처음보는 단어들에 대한 번역도 어느정도 수행이 가능해진다.
처음 보는 단어들의 대부분은 이름(name)이기 때문에, 동일한 표기법을 사용하는 경우 그대로 복사하는 것도 한 방법이고, 다른 표기법을 사용하는 경우 발음되는 대로 번역하는 것(transliteration)도 또 다른 방법이라고 할 수 있다. 또한, 해당 단어를 형태소(morpheme)로 나눠보는 시도들도 존재했다. 이번 논문에서 제안하는 방식은 back-off dictionary를 사용하지 않고도 open-vocabulary translation을 가능하게 한다.
# Byte Pair Encoding (BPE)

이번 논문에서는 BPE의 번형을 사용하게 된다. 기존의 BPE는 byte 단위의 연산을 수행한 반면, 이번에는 character 단위의 연산을 수행하기로 한다. 연산 방식은 동일한데, 모든 입력을 character 단위로 나눈 뒤, 가장 많이 등장하는 한 쌍을 골라서 하나의 유닛으로 결합한다. 이러한 과정을 정해진 vocabulary 집합의 크기가 될 때까지 반복해서 수행한다. 파이썬으로 구현된 알고리즘 예시는 [그림-1]과 같다. Test time에서 처음보는 새로운 단어를 만난 경우, 해당 단어를 character 단위로 분리한 후, vocabulary 집합 안에 있는 가장 큰 subword 단위로 합치게 된다. 이번 논문에서는 BPE를 적용한 두 가지 방법을 평가한다. 첫 번째 방법은 source/target 각각에 대한 인코딩을 사용하는 방식과, 두 번째로 source/target 을 합쳐서 하나의 인코딩을 사용하는 방식(joint BPE)을 사용한다.
# 성능 평가
우리는 BPE를 사용했을 때, 처음 보는 단어를 접한 경우 성능이 얼마나 좋아지는지와 어느정도 크기의 vocabulary size를 유지해야지 제일 좋은 성능을 제공할 수 있는지를 알아보려고 한다. 크게 두 가지 데이터셋을 사용한다. (English-German, English-Russian) 성능 측적을 위해서 BLEU와 CHRF3(character n-gram F3 score, 사람의 평가와 유사한 결과를 제공한다고 함)를 사용한다.
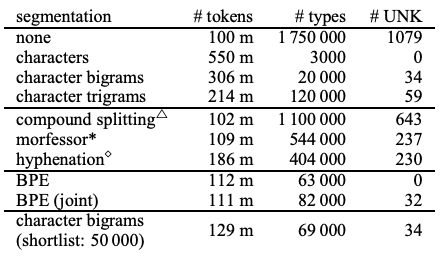
Baseline으로는 bilingual dictionary based on fast-align(WDict으로 표기) 모델을 사용한다. 해당 모델은 자주 등장하지 않는 rare word에 대해서 back-off dictionary를 사용한다. WUnk의 경우 back-off dictionary를 사용하지 않고, 처음 보는 단어를 접한 경우 모두 <UNK>로 표기하는 방벙이다. 또한, character n-gram에 대한 baseline도 지정하는데, n-gram의 경우 n의 크기가 성능에 큰 영향을 준다. unigram의 경우, 제대로된 open-vocabulary를 제공할 수 있지만, 성능이 좋지 않았기 때문에 bigram(char-bigram으로 표기)을 baseline으로 지정했다. 그외에도 다른 segmentation 들이 존재하지만(frequency-based compound splitting, rule-based hyphenation 등) open-vocabulary translation에 적합하지 않다고 판단되어 제외했다. English-German 데이터셋에 대한 segmentation 정보는 [표-1]과 같다.
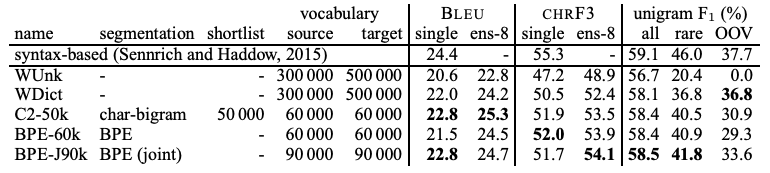
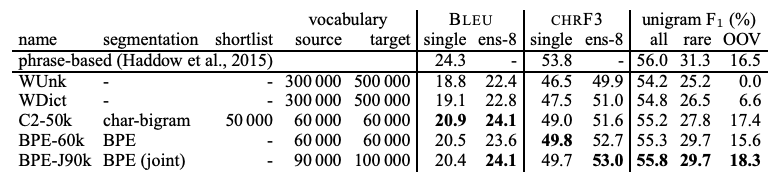
[표-2]는 English-German, [표-3]은 English-Russian translation의 성능을 보여준다. 모든 subword model들은 back-off dictionary를 사용하지 않고 동작한다. F1 점수를 보면, 모든 모델들이 baseline의 성능을 뛰어넘었다. OOV의 경우, 기존의 baseline에서 사용하는 방식(모르는 단어가 나타났을 때 그대로 복사하는 방식)이 효과적으로 적용될 수 있다. Rare word의 경우, 문장의 가장 중요한 의미를 담고 있는 경우가 많은데, BLEU나 CHRF3 점수로는 이러한 rare word의 중요한 성능을 정확하게 평가에 반영하지 못한다. 그럼에도 불구하고 제안하는 subword model을 사용했을 때 성능의 향상이 있었다.
# 추가적인 분석
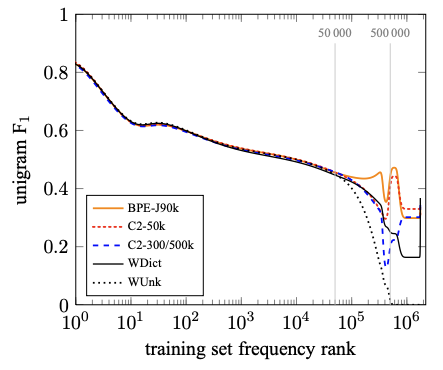
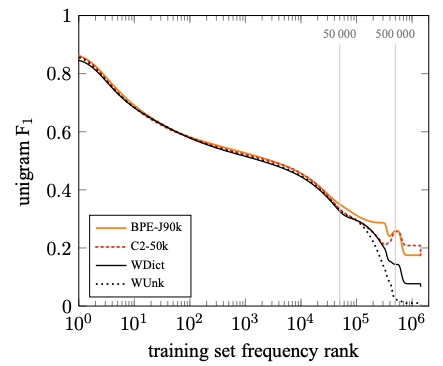
Vocabulary 집합의 크기가 성능에 어떠한 영향을 주는지 확인하기 위해 C2-3/500k 를 구축했다. 동일하게 bigram을 사용하지만, 집합의 크기가 훨씬 커졌다. [그림-2]와 [그림-3]은 각각 English-German, English-Russian 데이터셋에 대해서, rare word에 대한 unigram F1 점수를 나타낸다. 더 자주 나타나지 않는 단어일 수록, 성능을 떨어진다는 것을 확인할 수 있다. WDict의 성능이 WUnk의 성능보다 좋고, WDict의 성능보다 C2-3/500k의 성능이 더 좋다는 것을 확인할 수 있었다. Subword representation은 less sparse하기 때문에 vocabulary의 크기를 줄일 수 있고, 더 많은 단어들을 표현할 수 있기 때문에 더 좋은 성능을 제공할 수 있다. Subword model은 oversplitting을 해도 번역을 수행할 수 있고, transliteration도 수행할 수 있다.
# 관련 논문
On Using Very Large Target Vocabulary for Neural Machine Translation. : dictionary lookup 방식 (1)
Addressing the Rare Word Problem in Neural Machine Translation. : dictionary lookup 방식 (2)
Sequence to Sequence Learning with Neural Networks. : seq2seq (리뷰)
Neural Machine Translation by Jointly Learning to Align and Translate. : bahdanau attention (리뷰)
A New Algorithm for Data Compression. : Byte-Pair encoding
Learning Phrase Representations using RNN Encoder– Decoder for Statistical Machine Translation. : GRU
Integrating an Unsupervised Transliteration Model into Statistical Machine Translation : Transliteration
Can We Translate Letters? : character-based translation
Subword Language Modeling with Neural Networks.
Character-based Neural Machine Translation.
chrF: character n-gram F-score ´ for automatic MT evaluation. : chrF evaluation 방식
ADADELTA: An Adaptive Learning Rate Method. : adadelta
A Simple, Fast, and Effective Reparameterization of IBM Model 2. : bilingual dictionary based on fast-align




댓글